Benchmarking mRNA’s mRFP-expression#
In this notebook, we apply seqme to mRNA sequences.
import subprocess
from collections.abc import Callable
import numpy as np
import pandas as pd
import torch
from sklearn.linear_model import LinearRegression
import seqme as sm
device = "cuda" if torch.cuda.is_available() else "cpu"
Data#
Let’s download the mRNA sequences.
DATA_PATH = "mRFP_Expression.csv"
DATA_URL = "https://raw.githubusercontent.com/Sanofi-Public/CodonBERT/refs/heads/master/benchmarks/CodonBERT/data/fine-tune/mRFP_Expression.csv"
wget_command = ["wget", "-O", DATA_PATH, DATA_URL]
try:
subprocess.run(wget_command, check=True)
print(f"File downloaded successfully as {DATA_PATH}")
except subprocess.CalledProcessError as e:
print(f"Error occurred: {e}")
dataset = pd.read_csv(DATA_PATH)
train_data = dataset[dataset["Split"] == "train"]
eval_data = dataset[dataset["Split"] == "val"]
test_data = dataset[dataset["Split"] == "test"]
dataset.head()
| Sequence | Value | Dataset | Split | |
|---|---|---|---|---|
| 0 | AUGGCAUCAUCAGAAGACGUCAUAAAAGAAUUUAUGCGAUUCAAAG... | 10.164760 | mRFP Expression | train |
| 1 | AUGGCGUCUUCAGAGGAUGUAAUCAAGGAAUUCAUGCGUUUUAAGG... | 10.572869 | mRFP Expression | train |
| 2 | AUGGCAUCAUCGGAAGAUGUAAUAAAGGAAUUUAUGCGUUUCAAAG... | 9.766912 | mRFP Expression | train |
| 3 | AUGGCGAGUAGUGAAGACGUUAUCAAAGAAUUUAUGCGUUUUAAGG... | 9.926981 | mRFP Expression | train |
| 4 | AUGGCUUCUUCUGAGGACGUAAUAAAGGAGUUCAUGAGGUUCAAGG... | 9.857074 | mRFP Expression | train |
Models#
Let’s define the models.
class LinearRegressor:
def __init__(self, embedder: Callable[[list[str]], np.ndarray]):
self.embedder = embedder
self.regressor = LinearRegression()
def __call__(self, sequences: list[str]) -> np.ndarray:
return self.predict(sequences)
def predict(self, sequences: list[str]) -> np.ndarray:
embeddings = self.embedder(sequences)
return self.regressor.predict(embeddings)
def fit(self, sequences: list[str], labels: np.ndarray):
embeddings = self.embedder(sequences)
self.regressor.fit(embeddings, labels)
CACHE_PATH = None # "mrna_precomputed.pkl"
precomputed = sm.read_pickle(CACHE_PATH) if CACHE_PATH else None
cache = sm.Cache(init_cache=precomputed)
Lets setup the embedding model.
cache.add("RNA-fm", sm.models.RNAFM(verbose=True))
Lets setup a model predicting mRFP-expression (and train it).
xs = train_data["Sequence"]
labels = train_data["Value"]
regressor = LinearRegressor(embedder=cache.model("RNA-fm"))
regressor.fit(xs, labels)
cache.add("regressor", regressor)
100%|██████████| 4/4 [02:31<00:00, 37.83s/it]
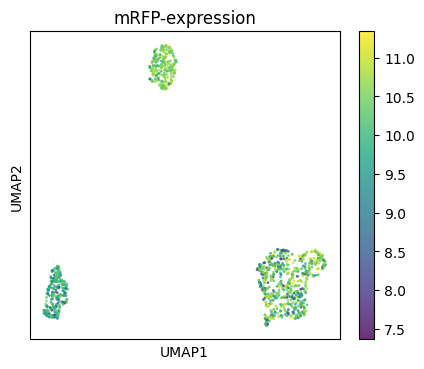
Let’s look at an UMAP of the mRNA using RNA-FM.
seqs = list(train_data["Sequence"])
values = np.array(train_data["Value"])
xs = cache.model("RNA-fm")(seqs)
xs_umap = sm.utils.umap(xs)
OMP: Info #276: omp_set_nested routine deprecated, please use omp_set_max_active_levels instead.
sm.utils.plot_embeddings(
xs_umap,
values=values,
title="mRFP-expression",
xlabel="UMAP1",
ylabel="UMAP2",
alpha=0.8,
point_size=4,
figsize=(5, 4),
)
Benchmark#
Let’s run the benchmark.
mRFP_sequences = list(test_data["Sequence"])
mRFP_shuffled = sm.utils.shuffle_characters(mRFP_sequences)
df = sm.evaluate(
sequences={
"mRFP": mRFP_sequences,
"mRFP (permuted)": mRFP_shuffled,
},
metrics=[
sm.metrics.ID(predictor=cache.model("regressor"), name="mRFP-expression", objective="maximize"),
sm.metrics.Threshold(
predictor=cache.model("regressor"),
name="mRFP-expression (>10.5)",
min_value=10.5,
),
sm.metrics.FKEA(embedder=cache.model("RNA-fm"), bandwidth=2.0),
],
)
100%|██████████| 1/1 [00:31<00:00, 31.83s/it]FP, metric=mRFP-expression]
100%|██████████| 1/1 [00:32<00:00, 32.38s/it] data=mRFP (permuted), metric=mRFP-expression]
100%|██████████| 6/6 [01:11<00:00, 11.98s/it, data=mRFP (permuted), metric=FKEA]
sm.show(df)
| mRFP-expression↑ | mRFP-expression (>10.5)↑ | FKEA↑ | |
|---|---|---|---|
| mRFP | 10.01±0.08 | 0.33 | 9.30 |
| mRFP (permuted) | -1.43±0.50 | 0.05 | 71.00 |
Let’s save the cache to a file.
CACHE_PATH = "mrna_precomputed.pkl"
sm.to_pickle(cache.get(), CACHE_PATH)